Selbstlernender Algorithmus
So lernen Maschinen denken

Selbstlernende Algorithmen, auch bekannt als maschinelles Lernen, sind zurzeit in aller Munde und finden in verschiedenen Branchen ihren Einsatz. In diesem Artikel wird der Fokus auf die Funktionsweise von selbstlernenden Algorithmen gelegt.
Was ist ein selbstlernender Algorithmus?
Im Gegensatz zu den klassischen Algorithmen, die entworfen wurden, um ein Problem zu lösen, dessen Lösung bereits bekannt ist, lösen selbstlernende Algorithmen Problemstellungen, deren Lösungen nicht klar definiert sind. Selbstlernende Algorithmen nutzen vorhandene Datenbestände, um Muster und Gesetzmäßigkeiten zu erkennen und Lösungen zu entwickeln. Beispiele für den Einsatz von Machine Learning sind die Vorhersage des Kaufverhaltens der Kunden oder die Klassifikation von E-Mails in Spam und Nicht-Spam.
Wie funktioniert ein selbstlernender Algorithmus?
Wie bereits zuvor beschrieben, verwenden selbstlernende Algorithmen Daten, um daraus Muster und Gesetzmäßigkeiten zu lernen. Hat der Algorithmus dann die Gesetzmäßigkeit erkannt, kann er mit neuen Daten gefüttert werden. Auf diese neuen Daten wird dann die vom Algorithmus gelernte Gesetzmäßigkeit angewandt und man erhält eine Lösung.
Dies impliziert aber auch, dass der Algorithmus neuen Daten dasselbe Verhalten unterstellt wie jenen Daten, aus denen er zuvor gelernt hat. Bilden also die Daten, aus denen der Algorithmus gelernt hat die Realität schlecht ab, so wird auch der Algorithmus schlechte Ergebnisse liefern. Daraus lässt sich schließen, dass die Qualität des Outputs wesentlich von der Korrektheit der Daten, von denen der Algorithmus lernt, abhängig ist.
Nehmen wir also an, ein Unternehmen will das Kaufverhalten seiner Kunden vorhersagen. Das Unternehmen verkauft sowohl Produkte in Shops als auch in einem Onlineshop. Um das Kaufverhalten der Kunden vorherzusagen, verwendet das Unternehmen einen selbstlernenden Algorithmus. Für den Lernprozess des Algorithmus werden jedoch nur jene Daten von Kunden genommen, die in den Shops einkauften. Somit unterstellt der Algorithmus auch Kunden aus dem Onlineshop dasselbe Kaufverhalten wie jenen aus den Shops.
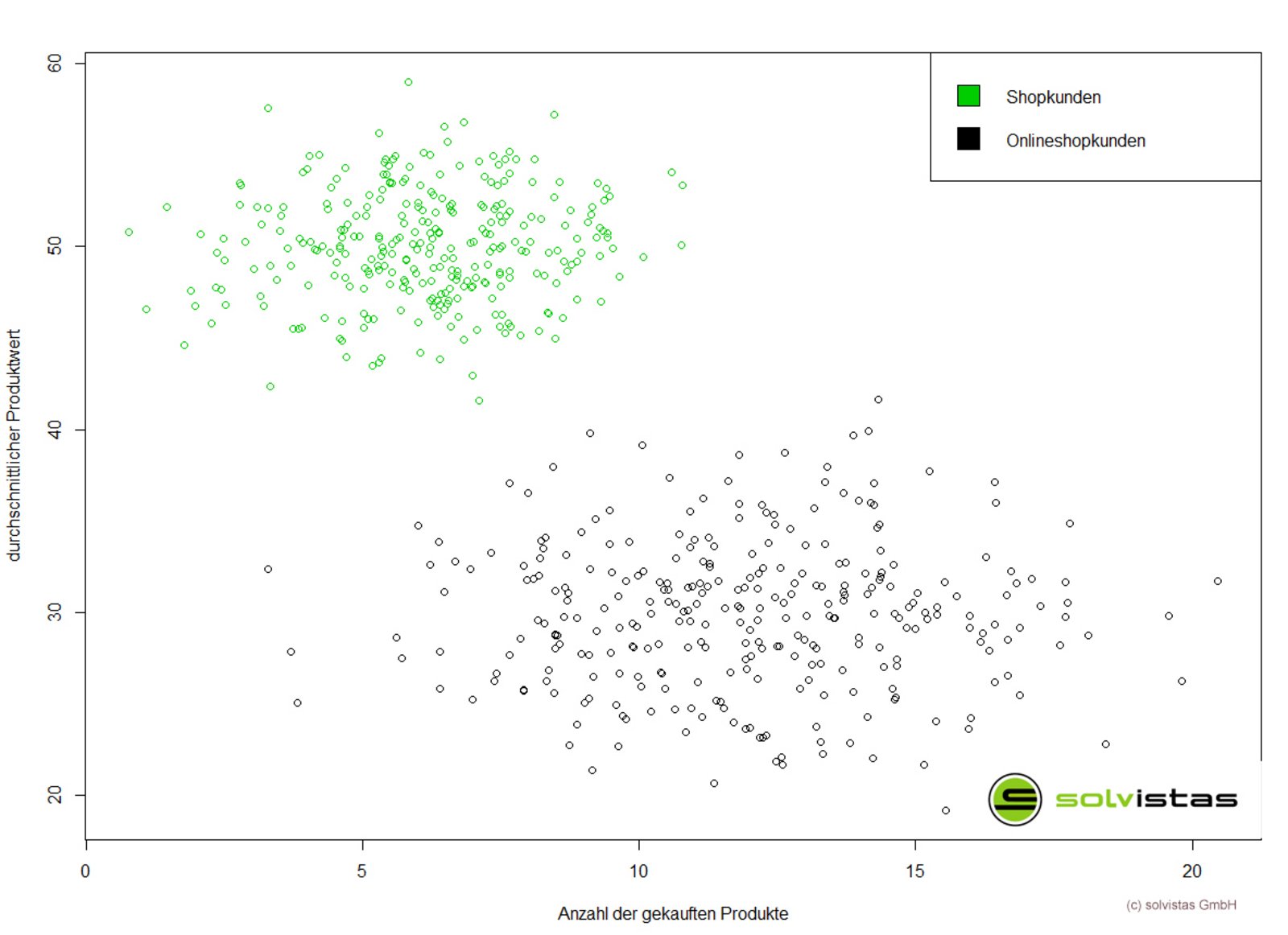
Jedoch, wie in der Grafik oben ersichtlich ist, kaufen Kunden aus dem Onlineshop tendenziell mehr Produkte mit einem geringeren Produktwert als Kunden in Shops, die eher weniger Produkte mit einem höheren Produktwert kaufen. Somit würde der selbstlernende Algorithmus das Kaufverhalten der Kunden des Onlineshops hinsichtlich der Anzahl der gekauften Produkte unterschätzen und hinsichtlich des Produktwerts überschätzen, da nur die Shop-Daten zum Lernen verwendet wurden.
Um solch ein Fehlverhalten des Algorithmus zu vermeiden und das Verhalten der Onlineshopkunden richtig abbilden zu können, müssen auch Daten aus dem Onlineshop zum Lernen verwendet werden.
Fazit
Zusammenfassend lässt sich sagen, dass selbstlernende Algorithmen ein hervorragendes Werkzeug sind, um aus Daten Wissen und Lösungen zu generieren. Dennoch muss man sich in der Praxis bewusst sein, dass die Qualität des Outputs wesentlich von der Qualität des Inputs abhängt.
Autorin: Michaela Raab




