Machine Learning – Alles auf einen Blick

Machine Learning ist jetzt schon seit einiger Zeit ein Thema, das immer mehr an Bedeutung gewinnt, wenn über Künstliche Intelligenz diskutiert wird. Aber was genau ist Machine Learning?
Welche verschiedenen Bereiche beinhaltet dieses Gebiet und wofür kann Machine Learning eingesetzt werden?
Machine Learning selbst ist ein Teilgebiet des großen Themenbereichs Künstliche Intelligenz. Es setzt sich aus Supervised Learning, Unsupervised Learning, Reinforcement Learning und dem Teilbereich Deep Learning zusammen.
Der Bereich Supervised Learning (Überwachtes Lernen) kann in zwei grundlegende Methoden aufgeteilt werden, und zwar in Regression und Klassifikation. Die Aufgabe der Algorithmen ist hierbei, Muster in den Daten zu finden, die in Zusammenhang mit den Zielwerten stehen und dadurch eine Zuordnung ermöglichen. Die Zielwerte bei der Klassifikation sind kategorisch, bei der Regression sind sie metrisch. Geschätzt (bzw. vorhergesagt) wird bei beiden Methoden.
Ein einfaches Beispiel für die Regression ist der Zusammenhang zwischen Wetter und Verkäufen (zeigt die Beziehung Temperatur zu verkauften Eiskugeln) oder Alter und Vermögen bzw. ausgegebenes Geld.
Ein Beispiel für die Klassifikation ist die Fähigkeit des Computers, visuelle Objekte zu erkennen und richtig zuzuordnen. Es wird mittels Labels (bekanntestes Beispiel sind Bilder mit Label “Hund” oder “Katze”) dem Algorithmus mitgeteilt, in welche Kategorien er die Daten einteilen soll. Das kann zur Kategorisierung von neuen Informationen, wie zum Beispiel dem Erkennen von Fehlern bei Produkten in der Produktion, dienen. Handschrift-Erkennung (also die Buchstaben bzw. Ziffern zu erkennen) stellt ein weiteres Klassifikationsbeispiel dar.
Wenn von Unsupervised Learning (Unüberwachtem Lernen) die Rede ist, wird mit unbeschrifteten Datensätzen gearbeitet. Einfach gesagt, ist das Wissen über die Daten zu Beginn der Arbeit gering. Die Dimensionsreduktion nutzt spaltenweise Zusammenhänge aus und fasst die Information in wenigen Attributen (fast) vollständig zusammen. Beim Clustering werden Gruppen von Beobachtungen (Objekten = Zeilen) gefunden. Des Weiteren gibt es dann auch noch die Assoziation, die Verbindungen zwischen Datenobjekten herstellt. Zum Beispiel: Jemand, der Produkt X kauft, kauft tendenziell auch Produkt Y.
Beim Reinforcement Learning werden Algorithmen so angelernt, dass sie selbstständig Entscheidungen treffen können. Der Fokus liegt auf der Entwicklung von intelligenten Lösungen für komplexe Steuerungsprobleme. Im Gegensatz zum Supervised und Unsupervised Learning werden keine Daten zur Konditionierung benötigt. Beim Reinforcement Learning werden die Daten in einem Trial- and-Error-Verfahren während des Trainings generiert und gleichzeitig mit einem Label versehen. Das Programm führt diverse Trainingsdurchläufe innerhalb einer Simulationsumgebung aus, um ein relativ genaues Ergebnis zu erbringen.
Unter Deep Learning versteht man Neuronale Netzwerke, die viele vernetzte Schichten besitzen. Man kann sich den Aufbau und die Funktionsweise dieser Netze wie eine Vereinfachung des menschlichen Gehirns vorstellen. Sie können Sprache, Text und Bilder analysieren. Viele der derzeitigen Technologien wären ohne diese Methoden nicht möglich.
Aktuelle Aufgaben bzw. Fragestellungen im Unternehmen zum Einsatz von Machine Learning in Wirtschaft und Forschung gibt es zahlreiche. Hier nennen wir nur einige, die bei uns im Unternehmen oft Anwendung finden:
- Prognose-Erstellung
- Klassifizierungsaufgaben
- Warenkorb-Analysen (Association Rules)
- Gruppen (Cluster) in Daten finden
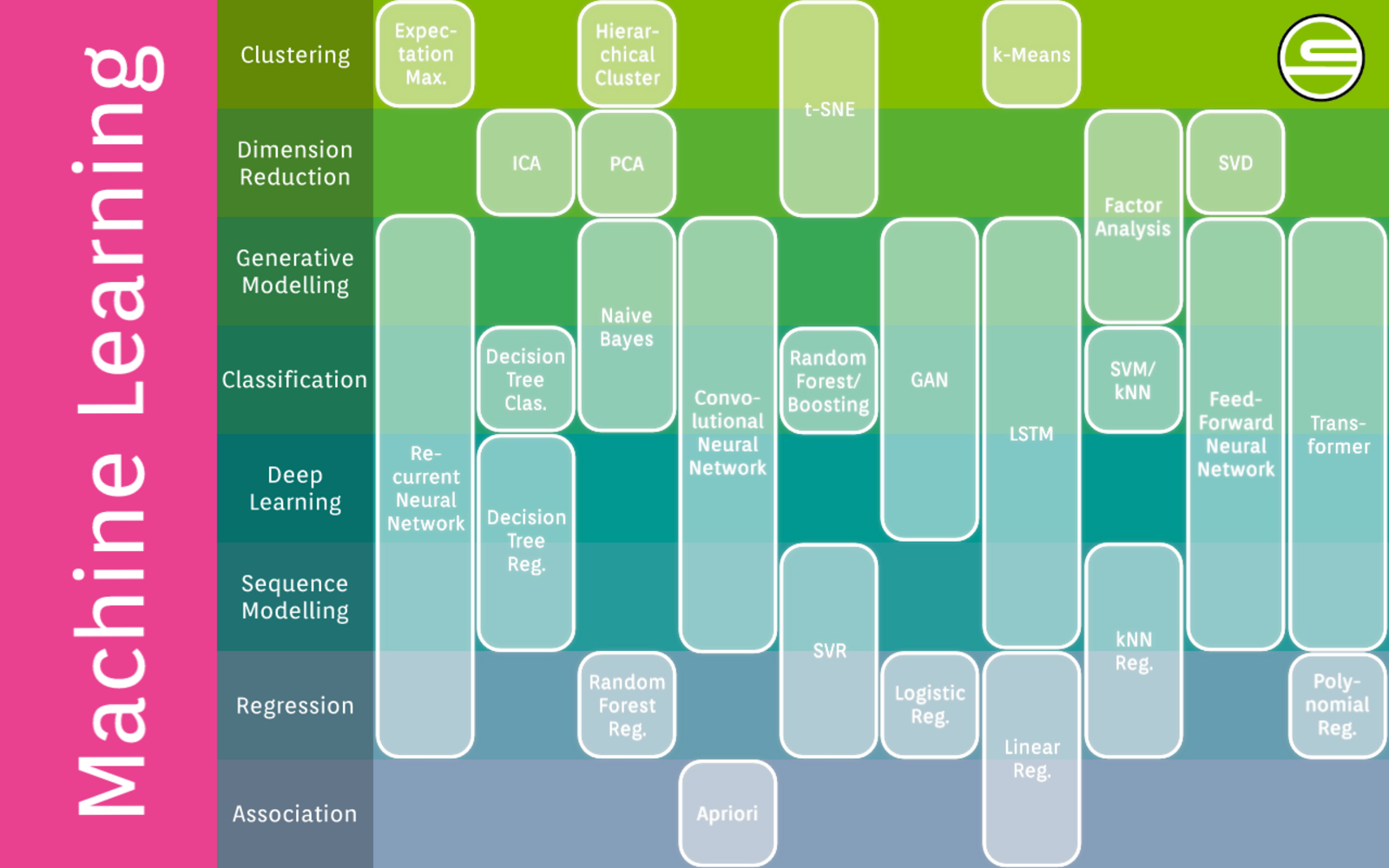
Je nach Zielsetzung und vorhandenen Daten werden unterschiedliche Algorithmen ausgewählt. In der täglichen Arbeit als Data Scientist ist es manchmal aufwändig, den Überblick über alle einsetzbaren Algorithmen für diese unterschiedlichen Aufgaben zu bewahren.
Die folgende Übersichtsgrafik dient als Reminder und zeigt auf einen Blick viele unterschiedliche Modelltypen. Somit wissen unsere Data Science Teams über die wichtigsten Parameter Bescheid und wählen den optimalen Algorithmus für unsere Kunden ;-)
Fazit
Unter Machine Learning als Teilbereich der Künstlichen Intelligenz verstehen wir Systeme, die selbständig Muster und Zusammenhänge aus großen Datenmengen lernen.
Supervised Learning ist sicher eine der am meisten angewendeten Methoden des Maschinellen Lernens. Die Einsatzgebiete sind weit gestreut, und reichen von Empfehlungssystemen über Vorhersagen wie etwa der Wahrscheinlichkeit einer Abwanderung eines Kunden bis hin zur Filterung von Spam-E-Mails oder Betrugserkennung – um nur einige zu nennen. Eine Auseinandersetzung mit dieser Thematik ist für Unternehmen lohnenswert, da die Chancen zur Verbesserung bestehender Prozesse und Produkte, aber auch die Entwicklung neuer und verbesserter Service- und Dienstleistungen außerordentlich sind.
Autorin: Klara Hultsch




