 Natural Language Processing (NLP) ist der Oberbegriff für das Erkennen, Erzeugen und Darstellen natürlicher Sprache durch den Computer. Für ein Unternehmen kann die Befähigung Texte automatisiert zu verarbeiten sowohl massive Zeitersparnis bedeuten, als auch gänzlich neue Möglichkeiten eröffnen.
Natural Language Processing (NLP) ist der Oberbegriff für das Erkennen, Erzeugen und Darstellen natürlicher Sprache durch den Computer. Für ein Unternehmen kann die Befähigung Texte automatisiert zu verarbeiten sowohl massive Zeitersparnis bedeuten, als auch gänzlich neue Möglichkeiten eröffnen.
Beispiel zur Anwendung von Natural Language Processing
Wir betrachten die Möglichkeiten und Methoden von NLP anhand eines Beispielprojektes, der Auswertung von Tätigkeitsberichten von Feldtechnikern. In diesem Beispiel geben die Feldtechniker ihre Berichte in einer Online-Maske als Freitext ein. Es werden über zahlreiche Techniker und Standorte hinweg hunderte Berichte pro Tag generiert, oftmals mehrere Berichte zum gleichen Problem. Die damit einhergehenden Herausforderungen beinhalten nicht nur potentielle Schreibfehler, sondern auch unterschiedliche Sprachen oder das Einfügen langer technischer Logs.
Ziel der NLP
Zielsetzung ist als erstes eine Kategorisierung der Berichte um Themenschwerpunkte zu ermitteln. Weiterführend sollen durch die gesamtheitliche Auswertung Erkenntnisse generiert werden welche durch das lesen einzelner Berichte nicht zu gewinnen sind. Dazu werden die Berichte mit weiteren Daten verknüpft welche Rahmenbedingungen beinhalten. Zum Beispiel ob die Reparatur Erfolg hatte, wie aufwendig sie war, Daten über den Standort und die verwendete Technik.
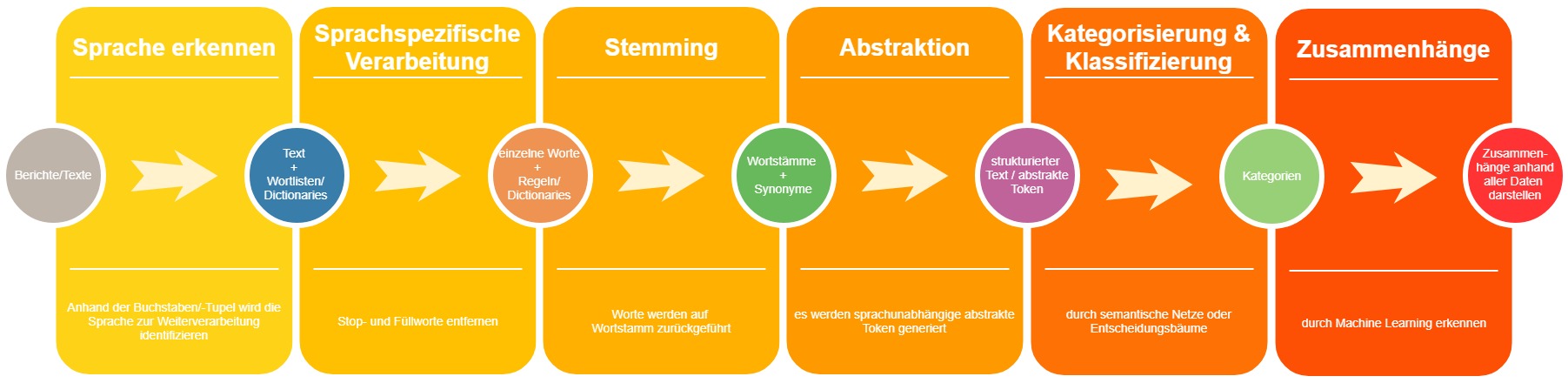
Workflow Natural Language Processing
Datenvorbereitung & Strukturierung
Sprache erkennen
Kommen wir zum interessanten Teil, der eigentlichen Verarbeitung. Bevor der Computer in der Lage ist die Tätigkeitsberichte zu verstehen müssen einige vorbereitenden Schritte erfolgen. Zuerst ermitteln wir die Sprache des jeweiligen Berichtes. Dazu werden im Text Buchstaben und Buchstaben Tupel gezählt, diese stehen in verschiedenen Sprachen in unterschiedlichem Verhältnis zueinander. Bereits nach einem Satz ist mit dieser Methode eine Genauigkeit erreicht welche die Erkennung der Sprache quasi fehlerfrei macht. Auch die technischen Einträge können auf diese Weise bereits identifiziert werden.
Sprachspezifische Verarbeitung
Als nächstes erfolgt mit Hilfe von Wortlisten und Dictionaries eine Sprachspezifische Verarbeitung. Es werden sogenannte Stop-Worte entfernt. Füllworte welchen im Rahmen der Sprachverarbeitung keine weitere Bedeutung zugemessen wird. Der erste Satz könnte dann so aussehen: „Natural Language Processing [ist] Oberbegriff Erkennen Erzeugen Darstellen natürlicher Sprache [durch] Computer“. Wenngleich sich dies für einen Menschen holprig liest nähert sich der Rechner einer Struktur an die er verstehen kann. Manche der Stop-Worte werden zwar entfernt, ihre Position und Bedeutung wird aber in den Metadaten zum Text beibehalten (ist,durch).
Stemming
Der nächste Schritt ist das Stemming. Dabei werden die einzelnen Wörter auf ihren Wortstamm zurückgeführt. Dies kann anhand von Regeln oder Dictonaries erfolgen. Der verbleibende Text ist nun bereits in einer Form in der er vom Rechner grob verarbeitet werden kann. Zum Beispiel durch einfache Aufzählung der Worte in den Texten. Dadurch lassen sich bereits Themengebiete oder Zusammenhänge ermitteln.
Abstraktion einführen
Ein interessanter Schritt ist nun ein weiterer Abstraktionsschritt. Dabei werden die Wortstämme und ihre Synonyme auf ein abstraktes Token zurückgeführt. Dies kann nun auch sprachübergreifend erfolgen. Damit ist unabhängig von der Ausgangssprache der Texte jeder Text mit seinem Inhalt maschinell erfasst. Erneut bietet sich an Kategorien zu bilden um bestimmte dominierende Themengebiete zu ermitteln welche mit der Tätigkeitsberichten in Zusammenhang stehen.
Kategorisierung & Klassifizierung
Neben den nun strukturierten Texten fließt nun ein semantisches Netz in die weitere Auswertung mit ein. Damit können nun Zusammenhänge erkannt werden welche vorher dem Rechner verborgen waren. Verschiedene Begriffe können zum gleichen Überbegriff gehören, wodurch Kategorien noch präziser Bestimmt werden können. Weitere Techniken wie Entscheidungsbäume können nun zur Klassifikation ebenfalls eingesetzt werden.
Zusammenhänge durch ML erkennen
Nun ist bereits das Zwischenergebnis erreicht das die eingehenden Tätigkeitsberichte der Feldtechniker automatisch klassifiziert und Kategorisiert werden können. Um die weiterführenden Ziele zu erfüllen werden nun mit der vorliegenden Datenbasis verschiedene Varianten des Machine Learning angewendet. Dabei werden zum Beispiel Modelle darauf trainiert einen Zusammenhang zwischen einer erfolgreichen Reparatur und den Tätigkeitsberichten herzustellen. Die bereits erzeugten Kategorien werden genutzt um verschiedene Fehlerbilder zu unterscheiden und aufgrund der künstlichen Erfahrung über alle Tätigkeitsberichte werden je Fehlerbild erfolgversprechende Maßnahmen ermittelt.
Ergebnis
Das System kann nun für Feldtechniker einen nennenswerten Mehrwert schaffen, da diese nun bei Arbeiten am Standort das Fehlerbild in einer Applikation beschreiben können und der Rechner ihnen bereits Vorschläge zum Vorgehen unterbreiten kann.
Autoren: Oliver Werth & Sophie Blank