Data Mining und Big Data vs. Statistik und Predictive Analytics
Den Überblick bewahren und die richtige Methode wählen

Im Zusammenhang mit Data Science fallen oft Begriffe wie Big Data, Data Mining, Predictive Analytics, Machine Learning und Statistik. Diese Themengebiete erfreuen sich in Zeiten der Digitalisierung großer Beliebtheit. Oftmals ist aber unklar, was mit diesen Begriffen überhaupt gemeint ist und inwiefern sie sich voneinander unterscheiden.
In diesem Artikel wird dem/der LeserIn ein grundlegendes Verständnis für die Definition dieser Begriffe und ihrer gegenseitigen Abgrenzung gegeben.
Als erste Orientierung dient die folgende Grafik:
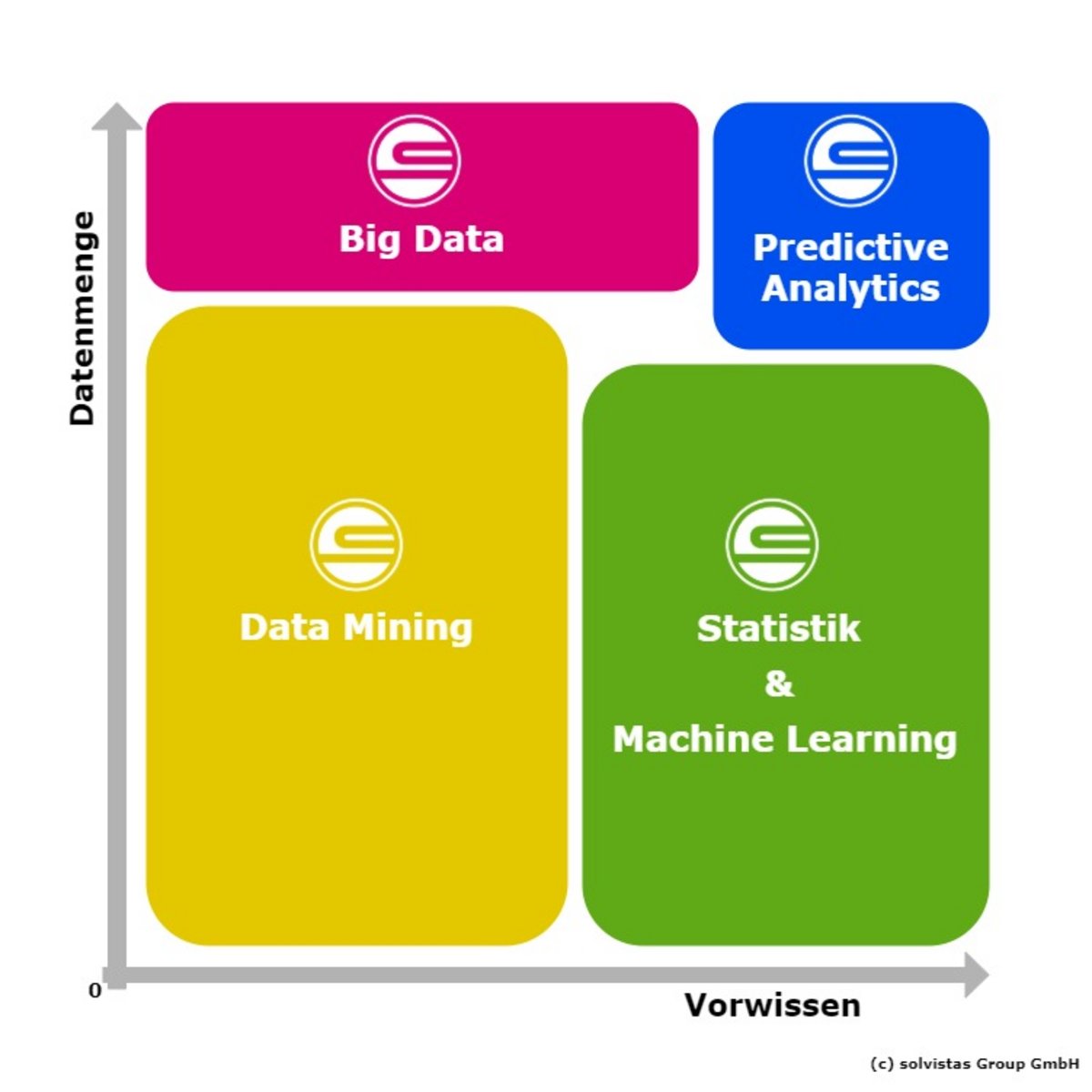
Der älteste Begriff in Zusammenhang mit Datenanalyse ist Statistik. Statistik beschäftigt sich mit der beschreibenden Auswertung von Daten und den Schlüssen, die aus diesen gezogen werden können. Zu diesem Zweck werden Hypothesen getestet und Modelle gebildet. Die angewandten Verfahren werden auch heute noch ständig weiterentwickelt, zum Beispiel können Simulationen nur mit großer Rechenpower durchgeführt werden. Grundlage der Statistik ist die Mathematik, insbesondere die Wahrscheinlichkeitsrechnung. Daher liegen statistischen Methoden zumeist Verteilungen zugrunde. Um derartige Annahmen treffen zu können, muss bereits Vorwissen über die Daten bestehen.
Wenn keine Annahmen über die Wahrscheinlichkeitsverteilung der Daten getroffen werden (können), stellt Machine Learning einen Lösungsansatz dar. Hierbei wird auf Basis von Trainingsdaten ein Modell erzeugt, welches auf neue Daten angewendet werden kann. Es wird zwischen Supervised und Unsupervised Machine Learning unterschieden.
Beim Supervised Machine Learning lernt der Algorithmus auf Basis von Daten-Paaren mit Eingangsgrößen und bekannten Ausgängen. Das so entstandene Modell kann dann auf Daten mit unbekannten Ausgängen angewendet werden und Ergebnisse vorhersagen.
Sind keine Informationen über die Resultate verfügbar, wendet man Unsupervised Machine Learning an. Dabei werden Strukturen - zum Beispiel Cluster, also Gruppen ähnlicher Elemente - in den Daten gefunden.
Wenn insgesamt wenig über die vorhandenen Daten bekannt ist, lohnt es sich, Data Mining anzuwenden. Im Zuge dessen werden die Daten durchsucht mit dem Ziel, interessante Muster oder Zusammenhänge – Korrelationen – zu entdecken. Aus den gewonnenen Erkenntnissen können dann Hypothesen abgeleitet und getestet oder Modelle angepasst werden. Für Data Mining hat sich ein Standardprozess etabliert, der das Vorgehen strukturiert. Dieser Prozess wird als CRISP-DM bezeichnet und wird auch von solvistas verwendet.
Die bisher erwähnten Methoden können im Prinzip auf Daten aller Art angewendet werden, unabhängig von der Dimension. Vor allem in den letzten Jahren wurden jedoch sehr große Datenmengen gesammelt, welche nach anderen Lösungsansätzen und Techniken verlangen. In diesem Zusammenhang spricht man von Big Data.
Obwohl dieser Begriff in aller Munde ist, existiert keine einheitliche Definition. Ein Zugang sind die sogenannten 4 Vs:
- Volume: Wie groß sind die Datenmengen?
- Variety: Wie unterschiedlich sind die Daten hinsichtlich Struktur und Inhalt?
- Veracity: Wie hoch ist der Wahrheitsgehalt der Daten - kann man ihnen vertrauen?
- Velocity: Mit welcher Geschwindigkeit und Häufigkeit nimmt die Datenmenge zu?
Oftmals wird auch ein fünftes V erwähnt, Value. Der Wert der Daten liegt in den aus der Analyse entstehenden Erkenntnissen und Möglichkeiten.
In keiner dieser Dimensionen existieren klare Grenzen, ab wann von Big Data die Rede ist, sie können aber als Indikatoren verstanden werden.
Big Data als Begriff umfasst aber nicht nur die Daten an sich, sondern auch die speziellen Methoden, die für den effizienten Umgang mit großen Datenmengen notwendig sind, wie zum Beispiel In-Memory-Technologien.

Die bisher erwähnten Herangehensweisen werden oftmals mit dem Ziel, Vorhersagen über Zukünftiges zu machen, eingesetzt. In diesem Zusammenhang ist dann die Rede von Predictive Analytics. Mithilfe von Techniken aus Statistik, Machine Learning und Big Data sollen möglichst detaillierte Forecasts erstellt werden. Dafür sind eine umfangreiche Datenbasis und der Einsatz moderner Technologien notwendig.
Predictive Analytics können zum Beispiel im Customer Relationship Management (CRM) eingesetzt werden, um Werbemittel gezielt und effizient einzusetzen.
Insgesamt kann man sagen, dass alle beschriebenen Themengebiete wichtige Teile der Data Science darstellen und die Grenzen nicht klar gezogen werden können. Statistik stellt die Basis für (fast) alle Methoden dar, durch neue Technologien haben sich aber weitere Felder ergeben, die mit Daten aller Art umgehen können.
Der wichtigste Aspekt ist auf jeden Fall, dass aus Daten Wissen gewonnen wird. Welcher Ansatz dafür am besten verwendet werden soll, ist von den vorhandenen Daten abhängig und muss von Fall zu Fall entschieden werden.
Autorin: Klara Hultsch




