 In Verbesserte Workflows mit Natural Language Processing (NLP) beschrieben Sophie und Oliver, wie Firmen NLP für die Auswertung von Tätigkeitsberichten von Feldtechnikern nutzen können.
In Verbesserte Workflows mit Natural Language Processing (NLP) beschrieben Sophie und Oliver, wie Firmen NLP für die Auswertung von Tätigkeitsberichten von Feldtechnikern nutzen können.
Eine weitere Anwendung für NLP ist Topic Modeling. Zum Beispiel die Extraktion von Themen aus Nachrichtenartikeln*. Hier versucht ein Algorithmus, aus Nachrichtentiteln Themen zu extrahieren. Im Beispiel unten hat das Programm erkannt, dass die Artikel „CeBIT, Banken & FinTechs: Bankenverband will auf der IT‑Messe die Brücke zu den FinTechs schlagen · IT Finanzmagazin“ etc. über das Thema „banken fintechs“ schreiben.
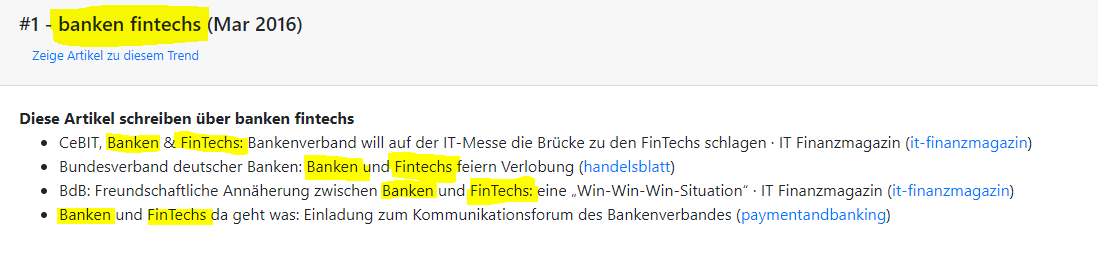
In den Artikeln erkennt das Programm das Thema „banken fintechs“
Wie diese Anwendung Natural Language Processing verwendet, beschreibt dieser Artikel mit Beispielen in Python.
Pipeline für Natural Language Processing
Damit ein Algorithmus menschliche Sprache verarbeiten kann, muss der Text speziell aufbereitet werden. Hierzu benötig man eine „NLP-Pipeline“, die die notwendigen Funktionen für die Textverarbeitung enthält. Das Ziel dieser Pipeline ist Standardisierung. Für das Topic Modeling bedeutet das, dass jeder Artikel mit den gleichen Funktionen verarbeitet wird. Es ist jedoch wichtig, dass diese Pipeline iterativ genutzt wird. Sobald das Programm in Produktion ist, müssen die Ergebnisse beobachtet werden. Wenn die Ergebnisse nicht den menschlichen Erwartungen entsprechen, muss die Pipeline angepasst werden. Somit können sogar Schritte wegfallen oder hinzukommen.
Für das Topic Modeling liefert folgende Natural Language Processing-Pipeline gute Ergebnisse:
- Case Conversion
- Stemming und Lemmatisierung
- Unerwünschte Symbole entfernen
- Stoppwörter entfernen
Case Conversion
Eine sehr einfache Art, Text zu standardisieren, ist Case Conversion. Dies macht man, um mit dem Text (z. B. beim Suchen) leichter arbeiten zu können. Hier kann der Entwickler zwischen Groß- und Kleinschreibung wählen. Für das Topic Modeling reicht Kleinschreibung:
>>> text = '5 Gründe, warum Versicherer die digitale Transformation brauchen · IT Finanzmagazin'
>>> text = text.lower()
>>> print(text)
'5 gründe, warum versicherer die digitale transformation brauchen · it finanzmagazin'
Stemming und Lemmatisierung
Ist der ganze Text klein geschrieben, muss man die einzelnen Wörter hinsichtlich Wortform standardisieren. Das funktioniert mit Stemming und Lemmatisierung. Das Stemming bringt ein Wort auf einen Wortstamm. Lemmatisierung ist ähnlich zu Stemming. Lemmatisierung bringt das Wort auf den Wortstamm, jedoch ist hier das finale Wort ein echtes Wort, d. h. ein Wort, das im Wörterbuch steht. Beim Stemming ist das finale Wort nicht immer ein Wort aus dem Wörterbuch.
import spacy
def stemm_words(text):
nlp = spacy.load('de')
spacy_doc = nlp(text)
stemmed_tokens = [token.lemma_ for token in spacy_doc]
stemmed_text = ' '.join(stemmed_tokens)
return stemmed_text
>>> text = '5 gründe, warum versicherer die digitale transformation brauchen · it finanzmagazin'
>>> text = stemm_words(text)
>>> print(text)
>>> '5 gründe , warum versicherer der digitale transformation brauchen · it finanzmagazin'
In diesem Beispiel hat die Funktion „die“ zu „der“ gemacht.
Unerwünschte Symbole entfernen
Der Text, den die NLP-Pipeline bearbeitet, enthält oft unerwünschte Symbole. Was ein unerwünschtes Symbol ist, hängt vom Projekt ab. Für das Topic Modeling sind zwei Arten von Symbolen unerwünscht:
- Satzzeichen
- Nicht-Text-Elemente
Satzzeichen entfernen:
import string
import re
def remove_special_characters(text):
tokens = tokenize_text(text)
pattern = re.compile('[{}]'.format(re.escape(string.punctuation)))
filtered_tokens = filter(None, [pattern.sub('', token) for token in tokens])
filtered_text = ' '.join(filtered_tokens)
return filtered_text
>>> text = '5 gründe , warum versicherer der digitale transformation brauchen · it finanzmagazin'
>>> text = remove_special_characters(text)
>>> print(text)
'5 gründe warum versicherer der digitale transformation brauchen · it finanzmagazin'
Die Funktion hat das „,“ entfernt.
Nicht-Text-Elemente entfernen:
def keep_text_characters(text):
filtered_tokens = []
tokens = tokenize_text(text)
for token in tokens:
if re.search('[a-zA-Z]', token):
filtered_tokens.append(token)
filtered_text = ' '.join(filtered_tokens)
return filtered_text
>>> text = '5 gründe warum versicherer der digitale transformation brauchen · it finanzmagazin'
>>> text = keep_text_characters(text)
>>> print(text)
'gründe warum versicherer der digitale transformation brauchen it finanzmagazin'
Hier hat die Funktion die „5“ und den „·“ vor „it finanzmagazin“ entfernt.
Beide Funktionen [keep_text_characters() und remove_special_characters()] rufen ganz am Anfang die Funktion tokenize_text() auf.
tokenize_text() tokenisiert den Text. Für Natural Language Processing ist Tokenisierung sehr wichtig.
Tokenisierung
Die Tokenisierung zerlegt den Text in kleinere Textbausteine. Es gibt zwei verschiedene Textbausteine:
- Sätze
- Wörter
Das Topic Modeling beachtet nur Artikeltitel. Da die Titel sehr oft aus einem Satz bestehen, reicht die Wort-Tokenisierung:
import nltk
def tokenize_text(text):
"""
Returns text tokenized as words
:param str text: Text to be tokenized
:return: Words
:rtype: String
"""
tokens = nltk.word_tokenize(text)
tokens = [token.strip() for token in tokens]
return tokens
>>> text = 'gründe warum versicherer der digitale transformation brauchen it finanzmagazin'
>>> text = tokenize_text(text)
>>> text
['gründe', 'warum', 'versicherer', 'der', 'digitale', 'transformation', 'brauchen', 'it', 'finanzmagazin']
In einer Natural Language Processing-Pipeline brauchen mehrere Schritte eine Tokenisierung. Zusätzlich zur Entfernung von unerwünschten Symbolen, benötigt auch die Entfernung der Stoppwörter eine Tokenisierung.
Stoppwörter entfernen
Stoppwörter sind Wörter, die für eine Anwendung keine Bedeutung haben. Es gibt zwei Arten von Stoppwörtern:
- Generische Stoppwörter: Diese Wörter sind für jede Anwendung gültig
- Spezielle Stoppwörter: Diese Wörter werden für eine Anwendung speziell entwickelt
Generische Stoppwörter
Die nltk-Bibliothek enthält generische Stoppwörter:
default_stopwords = set(nltk.corpus.stopwords.words('german'))
Da sind Wörter dabei wie: „der“, ‚aber‘, ’nur‘, ‚ob‘ …
Spezielle Stoppwörter
Die generischen Stoppwörter reichen jedoch nicht für jede Anwendung. Das Topic Modeling bspw. braucht zusätzliche Stoppwörter. Eines davon ist „finanzmagazin“. Finanzmagazin ist der Name einer Nachrichtenseite und erscheint sehr häufig in den Artikeltiteln. Das „verwirrt“ den Algorithmus insofern, dass dieser das Wort „finanzmagazin“ als Thema identifiziert.
Die Funktion, um spezielle und generische Stoppwörter zu entfernen, könnte so aussehen:
import codecs
import os
def remove_stopwords(text, custom_stopwords_file_name='industry_classifier_custom_stopword_list'):
default_stopwords = set(nltk.corpus.stopwords.words('german'))
all_stopwords = default_stopwords
if custom_stopwords_file_name:
custom_stopwords_file = os.path.join(BASE_DIR, 'machine_learning', 'stopwords', custom_stopwords_file_name + '.csv')
custom_stopwords = set(codecs.open(custom_stopwords_file, 'r', 'utf-8').read().splitlines())
all_stopwords = default_stopwords | custom_stopwords
tokens = tokenize_text(text)
filtered_tokens = [token for token in tokens if token not in all_stopwords]
filtered_text = ' '.join(filtered_tokens)
return filtered_text
>>> text = 'gründe warum versicherer der digitale transformation brauchen it finanzmagazin'
>>> text = remove_stopwords(text, custom_stopwords_file_name='topic_analysis')
>>> print(text )
'gründe warum versicherer digitale transformation brauchen'
Die Funktion hat drei Wörter entfernt: „der“, „it“, „finanzmagazin“.
Das eigentliche Topic Modeling
Jetzt ist der Text für das Topic Modeling fertig. Aus
5 Gründe, warum Versicherer die digitale Transformation brauchen · IT Finanzmagazin
wurde
Gründe, warum Versicherer digitale Transformation brauchen
Sobald die Pipeline für alle Artikel gemacht wurde, startet das eigentliche Topic Modeling. Die nächsten Schritte hierzu wären:
- Auf Basis aller Artikel eine TF-IDF-Matrix bauen (mittels sklearns TfidfVectorizer)
- Auf Basis dieser TF-IDF-Matrix mit einer Non-Negative Matrix Factorization (NMF) die Themen extrahieren (siehe sklearns NMF)
* Das basiert auf der Webanwendung des Autors
Bildquellen
- NLP_-panther_B80462292_web: Bildagentur Panthermedia